Kafka相关
Kafka
Kafka是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等。
Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
高性能
- 磁盘顺序读写
- 零拷贝:消息在磁盘到网络需要转换,零拷贝的作用就是通过减少用户态和内核态的转换,从而减少消息在磁盘到网络传输的资源损耗(通过SendFile方式)
- 压缩算法:生产者到broker经过压缩再传输
架构
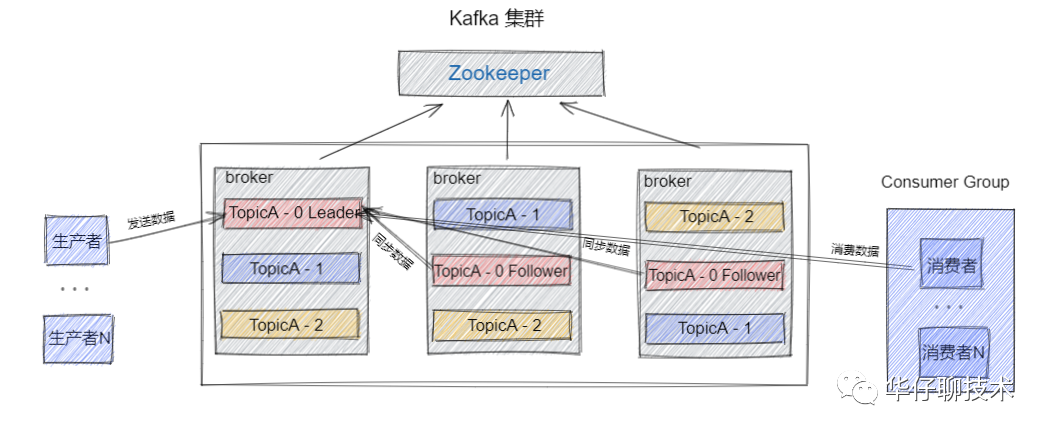
Kafka基础
- Topics(主题)
- Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)。
- Partition 消息分区
- 一个Topic下面会有多个Partition,每个Partition都是一个有序队列,Partition中的每条消息都会被分配一个有序的id。
- Brokers(经纪人、篮子)
- broker存储topic的数据。如果某topic有N个partition,集群有N个broker每一个服务器都是一个代理(Broker),那么每个broker存储该topic的一个partition。消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
- Producer 生产者
- 生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
- Consumer 消费者
- 消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
- Consumer Group 消费组
- 消费者分组,将同一类的消费者归类到一个组里。在Kafka中,多个消费者共同消费一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个组名。
- Leader
- 每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
- Follower
- Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
- Client和Server之间的通讯,是通过一条简单、高性能并且和开发语言无关的TCP协议。并且该协议保持与老版本的兼容。
队列和发布-订阅式
队列的处理方式是 一组消费者从服务器读取消息,一条消息只有其中的一个消费者来处理。在发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。 消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。 假如所有的消费者都在一个组中,那么这就变成了queue模型。 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。
消费组
- 单播消费:一条消息只能被一个消费者消费:两个消费者topic,group.id都相同,那么只有一个消费者能消费消息
- 多播消费:一条消息能被多个消费者消费(发布订阅模式),两个消费者topic相同,group.id不同,这样两个消费者都能消费
每个消费者基于自己在commit log中的消费进度(offset)来进行工作,offset由消费者自己维护,也可以指定offset消费
分区
一个topic下可以有多个分区partition日志文件
partition是一个有序的message序列,每个分区对应一个commit log文件
kafka一般不会删除消息,它会根据日志保留时间(log.retention.hours=168)确认消息多久被删除
log.retention.hours参数:config/server.properties
数据文件存在配置地方(log.dirs=/usr/local/data/kafka-logs)
发送者参数
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.7:9092,...")
// 发送消息持久化参数ack=0:发送不需要等待broker确认收到消息,直接继续发送
// ack=1:发送需要等待leader将数据写入本地Log,然后继续发送(follower没保证,如果leader挂掉,消息丢失)
// ack=-1 or all:发送需要等待follower成功写入,然后继续发送(等待几个follower成功写入可以配置:min.insync.replicas默认是1)
props.put(ProducerConfig.ACKS_CONFIG, "1");
// 发送消息失败重试
ProducerConfig.RETRIES_CONFIG,3
// 重试间隔时间
ProducerConfig.RETRY_BACKOFF_MS_CONFIG,300(ms)
// 发送消息本地缓存区,消息会先发送到缓存区默认32M,然后本地线程会从缓存区取数据到batch(默认16K),然后批量发送消息
ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432
// batch大小(一次批量最大发送消息大小)
ProducerConfig.BATCH_SIZE_CONFIG, 16384
// batch不是一定要满16K才发送,会到点发送,默认10MS,没满也发送
ProducerConfig.LINGER_MS_CONFIG, 10消费者参数
// 是否自动提交offset,默认true,自动提交一般会存在问题,一般用手动提交(consumer.commitSync();)
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true")
// 一次poll最大拉取消息的数量,默认500
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500)
// 如果两次poll操作间隔时间超过这个配置,broker认为这个消费者能力太弱,会把它剔除消费组
ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000
// 心跳间隔时间,消费组会给broker发送心跳,保证长连接
ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 3000
// broker多久感知不到消费者的心跳就认为它故障,将其踢出消费组
ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000
// 自动重置offset,latest默认:只消费自己启动之后发送到主题的消息
// earliest:第一次从头开始消费,以后按照offset消费
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"
// 指定分区消费
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)))
// 消息回溯消费
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)))
consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)))
// 指定offset消费
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)))
consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10)// 指定时间点消费
try {
long startTime = System.currentTimeMillis() - 1000 * 60 * 60
Map<TopicPartition, Long> partitionLongMap = new HashMap<>();
// 拿到所有topic的分区
for (TopicPartition topicPartition : collection) {
partitionLongMap.put(new TopicPartition(topic, topicPartition.partition()), startTime);
}
// 根据时间找到offset
Map<TopicPartition, OffsetAndTimestamp> map = consumer.offsetsForTimes(partitionLongMap);
// 对每个分区用consumer.seek,指定offset消费
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : map.entrySet()) {
TopicPartition partition = entry.getKey();
OffsetAndTimestamp value = entry.getValue();
long offset = value.offset();
consumer.seek(partition, offset);
}
} catch (Exception e) {
log.error("kafka设置从指定时间戳开始消费 SaveOffsetOnRebalanced 出错", e);
}总控制器Controller
Kafka集群有一个或多个broker,需要选举一个控制器Controller,负责管理集群所有分区和副本状态
- 当分区的leader副本故障时,controller负责选举分区新的leader
- 当检测到分区的ISR集合变化时,controller负责通知所有broker更新元数据信息
- 当增加topic分区数量时,controller负责让新分区被其它节点感知到
controller选举机制:
- 首先启动的broker就是controller
- 选举的时候每个broker都尝试在zookeeper上创建/controller临时节点,zookeeper会保证只有一个创建成功,成功那个就是controller
分区副本选举leader
分区副本leader由controller监控感知,leader挂了,controller会感知到,然后从ISR列表选第一个作为新leader,如果ISR没有其它副本了,根据参数unclean.leader.election.enable(true or false):
true:在ISR列表外选一个作为leader(ISR里的副本性能好,数据基本都同步了,ISR外的可能有数据没有同步)
false:等待ISR列表机器恢复
副本进入ISR列表条件:
- 副本节点不能产生分区,必须与zookeeper保持会话以及跟leader副本网络连通
- 副本能复制leader上所有写操作,不能落后太多
消费者offset
每个消费者会定期将offset发给kafka的topic __consumer_offset,key:consumerGroupId+topic+分区,value:offset值,这个topic默认50个分区
提交到哪个分区:hash(consumerGroupId % __consumer_offsets分区数量)
消费者rebalance
触发rebalance:
- 消费者组里的consumer增加了
- topic分区增加了
- 消费组订阅了更多topic
注:如果消费者指定了分区消费,则不触发rebalance
rebalance过程中无法消费消息,尽量避免高峰期触发rebalance
rebalance分配策略
比如10个分区(0-9),3个消费者
range: 平均分,0-3分区 -> consumer1 | 4-6分区 -> consumer2 | 7-9分区 -> consumer3
round-robin轮询:把分区依次给消费者:consumer1:0,3,6,9 | consumer2:1,4,7 | consumer3:2,5,8
sticky:初始分配和轮询一样,但是触发rebalance时保证两个原则
- 分区分配尽可能均衡
- 分配与上一次尽量相同(尽量让已经分配了的不要重新分配)
HW和LEO
HW高水位,LEO(log-end-offset最大offset),HW就是取ISR中最小的LEO,consumer消费时最多只能消费到HW(leader新写入消息时,consumer不能马上消费,需要等到ISR中的副本同步完全,全部同步后HW更新,这时候consumer就能消费新消息了)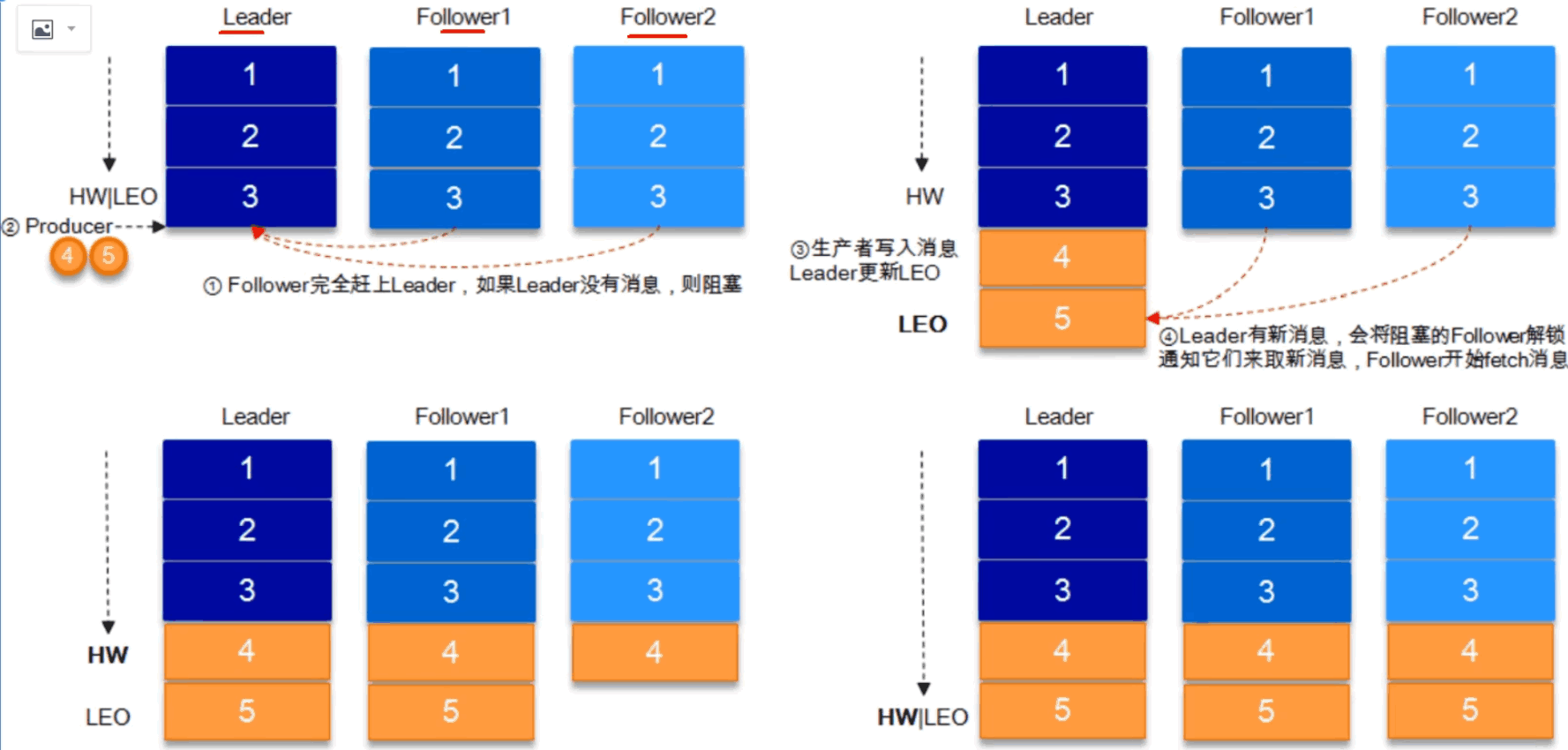
实战规划
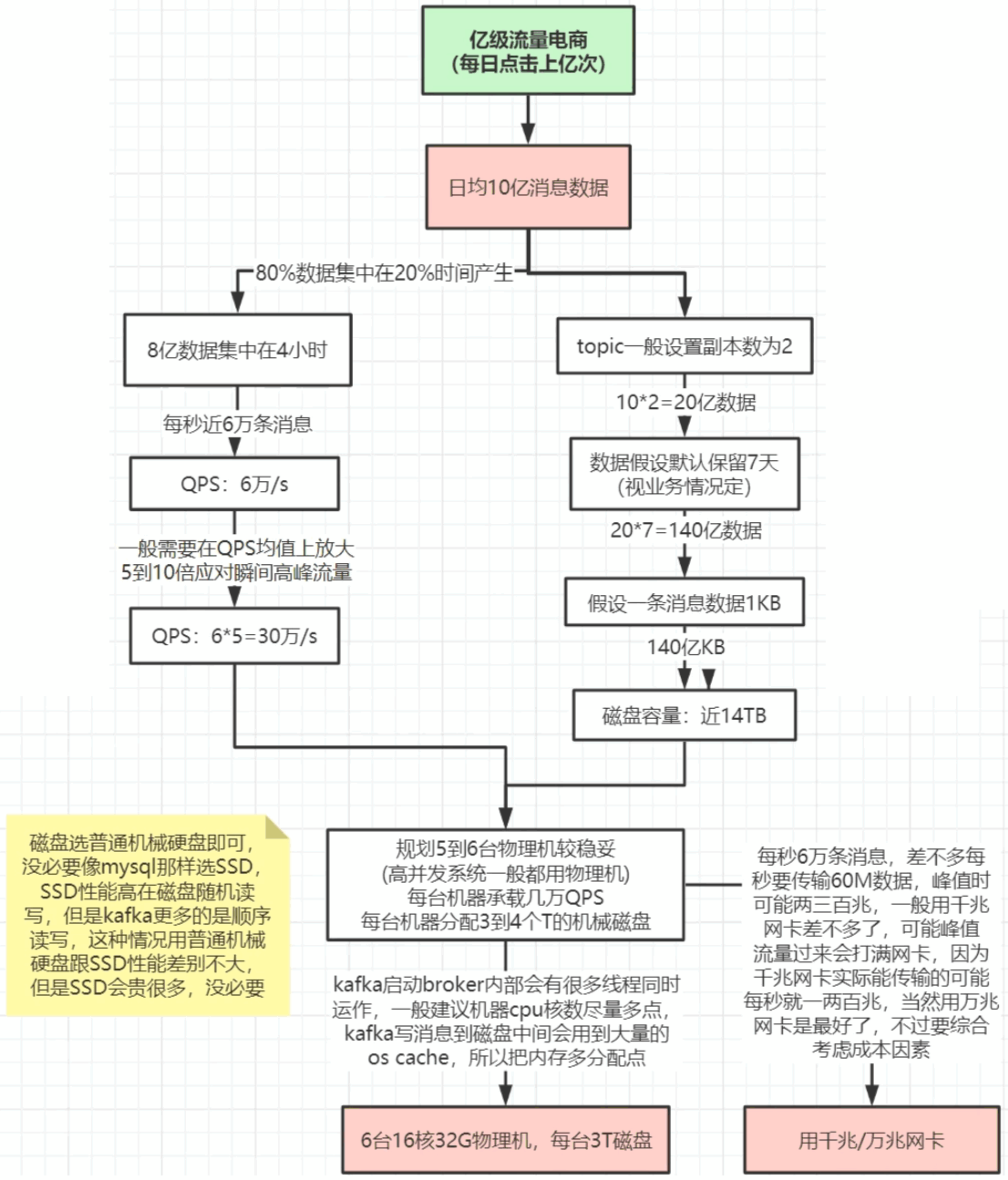
JVM配置
32G机器
export KAFKA_HEAP_OPTS="-Xmx16G -Xms16G -Xmn10G -XX:MetaspaceSize=256M -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:G1HeapRegionSize=16M"需要预留操作系统缓存的内存OS cache
线上问题
消息丢失
- 保证发送者不丢失,设置ack=all
- 消费端不丢失,设置手动提交offset
消息重复消费
- 发送端:发送端如果配置了重试,根据网络等原因,消息会重复发送
- 消费端:如果是自动提交,可能也会重复消费
解决:一般对消费者做消息幂等处理,比如根据版本号判断消息是否消费过
顺序消费
- 发送端需要同步发送,然后发送到一个分区
- 消费端需要用一个消费者消费一个分区
上面的性能很低,可以在消费者收到消息后放到队列,然后开多线程处理
消息积压
- 消费者性能问题:可以修改消费者程序,或者下一个消费者,上一个新的消费者,新的消费者逻辑把消息转发到另一个topic,新的topic上很多分区和消费者处理消息
- 消费者程序有BUG:把消费不成功有BUG的消息转发到其它队列,然后慢慢分析问题
延时队列
本身不支持
可以先把消息发送到指定的topic(topic_30s topic_30m),然后通过定时器轮询消费这些topic,查看消息是否到期,到期就发送到业务topic,没到期就结束这次轮询,下一次仍然判断这条消息(先消费的是先发的消息,后面的不用判断)
消息传递保障
- at most once消费者最多收到一次消息,ack=0可以实现
- at least once消费者至少收到一次消息,ack=all可以实现
- exactly once消费者刚好收到一次消息,需要实现消费幂等才行
kafka事务
这个事务不是rocket的事务,它是保证kafka消息的事务一致性(发送者发送3条消息,要么全部成功,要么全部失败)
Properties properties = new Properties();
properties.put(org.apache.kafka.clients.producer.ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionId);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
// 初始化事务
producer.initTransactions();
// 开启事务
producer.beginTransaction();
try {
// 处理业务逻辑
ProducerRecord<String, String> record1 = new ProducerRecord<String, String>(topic, "msg1");
producer.send(record1);
ProducerRecord<String, String> record2 = new ProducerRecord<String, String>(topic, "msg2");
producer.send(record2);
ProducerRecord<String, String> record3 = new ProducerRecord<String, String>(topic, "msg3");
producer.send(record3);
// 处理其他业务逻辑
// 提交事务
producer.commitTransaction();
} catch (ProducerFencedException e) {
// 中止事务,类似于事务回滚
producer.abortTransaction();
}
producer.close();相关
Producer 端生产的消息会不断追加到 log 文件末尾,为了防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制。
每个 Partition 分为多个 Segment每个 Segment 对应3个文件(1. index索引文件; 2. log数据文件; 3. timeindex时间索引文件)
分区可以设置多个副本,保证数据安全,每个副本都有角色,它们会选取一个副本作为 Leader 副本,而其他的作为 Follower 副本
生产者发送消息只能发送到Leader,然后follwer会去leader同步数据,消费者消费数据也只能从leader消费
同一个分区下的所有副本保存相同的消息数据,这些副本分散保存在不同的 Broker 上,保证了 Broker 的整体可用性。
所有的读写请求都必须先发往 Leader 副本。Follower 副本唯一的任务就是从 Leader 副本异步拉取消息,并写入到自己的提交日志中,从而实现与 Leader 副本的同步。
分区并不是越多,吞吐量越高,需要测试
相关命令
bin/kafka-topics.sh --create --bootstrap-server 192.168.31.7:9092 --replication-factor 3 --partitions 2 --topic testTopic
bin/kafka-topics.sh --describe --bootstrap-server 192.168.31.7:2181 --topic testTopic
