Java集合
Collection
public interface Collection
AbstractCollection
public abstract class AbstractCollection
此类提供 Collection 接口的骨干实现,以最大限度地减少了实现此接口所需的工作。
Map
HashMap
HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现
1.7数组 + 链表
1.8数组 + 链表 + 红黑树(链表>8改用红黑树)
hash冲突时使用链表,链表1.7采用头部插入,1.8用的尾插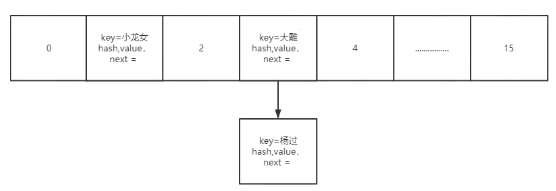
参数loadFactor 加载因子
loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据(entry)也就越少,也就越稀疏。
loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。
默认容量为 16,负载因子为 0.75。当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
容量可以配置,必须为2的指数次幂(在hashcode后转index需要将hashcode和容量 - 1进行 与 运算,这里容量需要2的指数次幂)(如果不是会自动转成2的指数次幂,比如9转成16【大于9,然后最接近9的2次幂的数】)
put
大致流程:put时候会判断是否初始化,没有就初始化。然后往数组放。
放的过程:首先对key进行hashcode(还做了一定位运算,让hash分布更均匀)
然后把hashcode和容量 - 1进行 与 运算,得到index,然后赋值tab[index] = newNode;
n = (tab = resize()).length;
tab[i = (n - 1) & hash]
其中2的任意指数次幂都是10000(1后面都是0),-1后都是(0000111),最后面都是111111
1011 0111 1011 1001
0000 0000 0000 1111
& 运算后结果都在0000-1111之间(值在容量范围内,并且每个值都有可能取到)
其中这里用&运算因为这种位运算最接近机器语言,效率更高,%取余这种效率大概比&少10倍扩容
size >= threshold:数组使用率达到阈值后就会扩容,扩容为原来2倍
JDK1.7扩容新建一个2倍大的数组,然后循环(链表也要循环)把之前的数据迁移到新数组(迁移后会rehash,位置会变)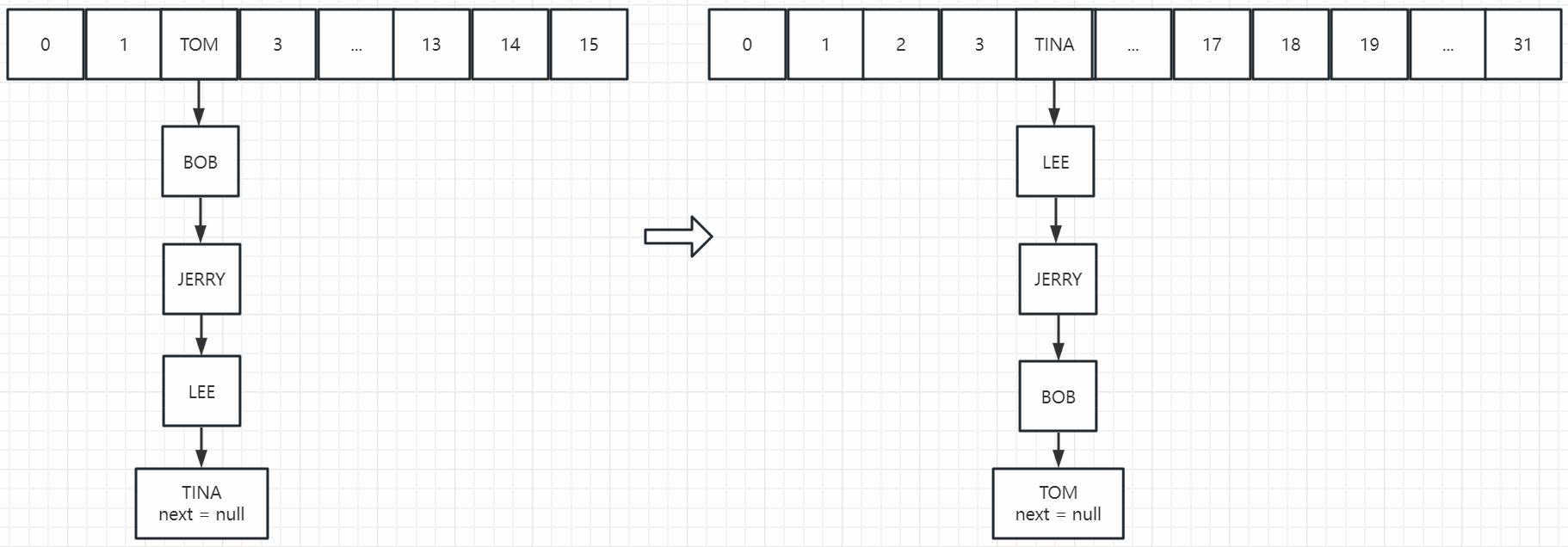
JDK1.7多线程扩容的时候,数据迁移后可能链表成环(头插法引起)。这样数据再次插入到同一个hash桶(遍历链表)会无线循环,找不到next -> null
JDK1.8扩容利用4组高低位指针,遍历把一个桶分成两组链表,高位和低位链表(hash & 容量 > 0就是低位,反之就是高位)(任一值 & 2的指数次幂(容量)只有两种结果->容量 | 0)
然后把低位链表移动到新数组,相同的index的位置,高位链表移动到新数组(index + 容量)的位置(扩容之后的另一半空间),不需要rehash(需要满足容量为2的指数次幂)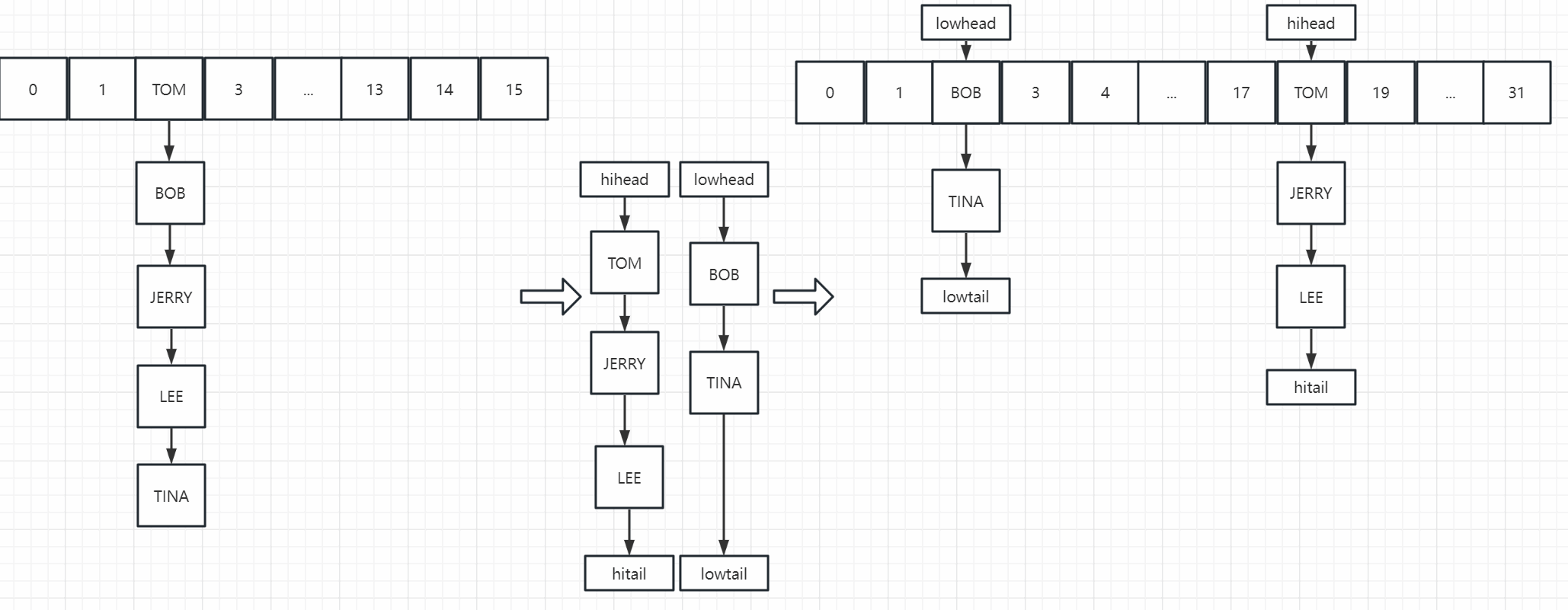
1.8引入红黑树,链表大于8使用红黑树,但是有条件(会先判断数组容量是否<64,小于64就直接扩容,大于等于64改用红黑树,)
为什么选8,根据泊松分布,正常情况,链表达到8的概率十分小,HashMap注释有写
ConcurrentHashMap
数据结构和HashMap类似,区别:
- 写数据加了同步,读是无锁
- 扩容时数据转移是多线程转移,性能稍高
1.7
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
创建ConcurrentHashMap时会new一个Segment
put时会根据key.hashcode计算大概的范围(在哪个segment里面),然后对这个segment加锁(竞争锁),然后操作这个segment里面的hashmap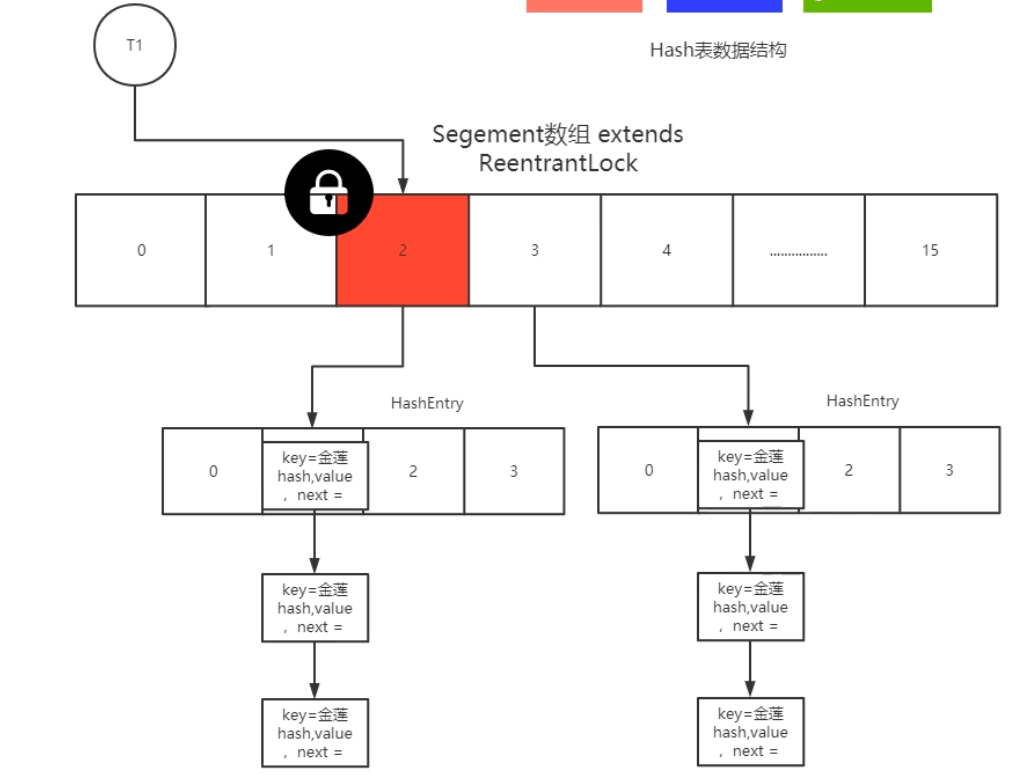
1.8
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。
结构去掉segment,用一个大数组Node + 链表 / 红黑树(和HashMap一样的数据结构),Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
相关参数:
MIN_TRANSFER_STRIDE: 默认16,table扩容时,每个线程最少迁移table槽位个数
MOVED:值为-1,Node.hash = MOVED时,代表table正在扩容
nextTable:table迁移过程中的临时变量,迁移过程中将全部元素迁移到nextTable上
sizeCtl:标志table初始化和扩容【0:table还没初始化 -1:table正在初始化 小于-1:table正在扩容 大于0:初始化完成后,代表table最大存放元素个数】- put:最外层有一个for循环,保证一定做完这个put操作,首先判断是否初始化,没有就初始化(初始化需要CAS)
然后和HashMap一样key.hashcode & (n-1),拿到index,判断table[index]是否为null,为null就CAS往里面放数据,不为null再判断是否扩容,扩容就调用扩容,否则就synchronized加锁往链表/红黑树放数据pub(key, value, onlyIfAbsent) { hash = key.hashCode for(){ if 初始化 if (table[index] == null) { // index和HashMap一样通过hash & (容量 -1) 得到 这个坑没人用过,CAS往里面放 } else if (是否在扩容) { 执行扩容逻辑(帮助扩容,判断是否扩容完成,是否达到最大扩容线程,满足帮助扩容条件就帮助扩容,每个线程默认分配扩容16个槽位) } else { synchronized(f) { // 锁加在table[index]这个对象上,大数组里面装的index下的对象 构建链表/红黑树逻辑,首先循环判断链表/红黑树中是否存在插入值,存在就替换,不存在就加在链表后面 } } } }
TreeMap
TreeMap存储 Key-Value 对时,需要根据 key-value 对进行排序。线程不安全,TreeMap 可以保证所有的 Key-Value 对处于有序状态。插入和遍历顺序不一致
TreeSet底层使用红黑树结构存储数据
HashTable
Hashtable是个古老的 Map 实现类,JDK1.0就提供了。不同于HashMap,Hashtable是线程安全的。
底层都使用哈希表结构,查询速度快,很多情况下可以互用。
与HashMap不同,Hashtable 不允许使用 null 作为 key 和 value
LinkedHashMap
LinkedHashMap 是 HashMap 的子类
在HashMap存储结构的基础上,使用了一对双向链表来记录添加元素的顺序
与LinkedHashSet类似,LinkedHashMap 可以维护 Map 的迭代顺序:迭代顺序与 Key-Value 对的插入顺序一致
List
ArrayList Vector LinkedList
ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
LinkedList: 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
CopyOnWriteArrayList
线程安全,同时读写,读写分离,空间换时间
使用读多写少,最大程度提高读效率,经常写不适合
最终一致性,写过程原有的数据不会改变
只有volatile才能保证其它 线程及时读到新的数据
不存在扩容概念,写的时候copy一个副本写,但是不能并发写,需要对写操作加锁(任一时候只能有一个线程写)
写完之后副本变正本,以前的丢弃(等所有线程读完后丢弃)
Set
public interface Set
一个不包含重复元素的 collection
HashSet LinkedHashSet TreeSet
HashSet:底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
LinkedHashSet:底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。(插入和遍历顺序一致)
TreeSet:底层数据结构采用红黑树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造),自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储
TreeSet类型是J2SE中唯一可实现自动排序的类型
CopyOnWriteSet
CopyOnWriteSet线程安全的集合,底层基于CopyOnWriteArrayList,和CopyOnWriteArrayList基本一样,多了保证元素唯一
synchronized锁升级
synchronized锁有四种状态:无锁,偏向锁、轻量级锁和重量级锁
原始的synchronized是直接使用重量级锁,才会导致性能很低,加入锁升级才使得synchronized性能获得很大提升。
- 当一个对象被创建之后,还没有线程进入,这个时候对象处于无锁状态
- 当锁处于无锁状态时,有一个线程A访问同步块并获取锁时,会在对象头和栈帧中的锁记录记录线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来进行加锁和解锁,只需要简单的测试一下啊对象头中的线程ID和当前线程是否一致。在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,因此为了减少同一线程获取锁带来的开销,所以引入偏向锁。
- 偏向锁的基础上,又有另外一个线程B进来,这时判断对象头中存储的线程A的ID和线程B不一致,就会使用CAS竞争锁,并且升级为轻量级锁,会在线程栈中创建一个锁记录(lock Record),将Mark Word复制到锁记录中,然后线程尝试使用CAS将对象头的Mark Word替换成指向锁记录的指针,如果成功,则当前线程获得锁;失败,表示其他线程竞争锁,当前线程便尝试CAS来获取锁。
- 当线程没有获得轻量级锁时,线程会CAS自旋来获取锁,当一个线程自旋10次之后,仍然未获得锁,那么就会升级成为重量级锁。成为重量级锁之后,线程会进入阻塞队列(EntryList),线程不再自旋获取锁,而是由CPU进行调度,线程串行执行。
参考:https://blog.csdn.net/weixin_45794641/article/details/123255683

