MySQL一篇概全
存储引擎
MyISAM
不支持事务 不支持外键 不支持行锁
适用执行大量select
InnoDB
支持外键 支持事务 支持行锁 一致性的不加锁读取(快照读)
不保存表的行数 count(*)需要扫整表
根据主键索引组织起数据(必须有主键,索引)
Memory
数据存储内存 表结构存储磁盘 访问效率高
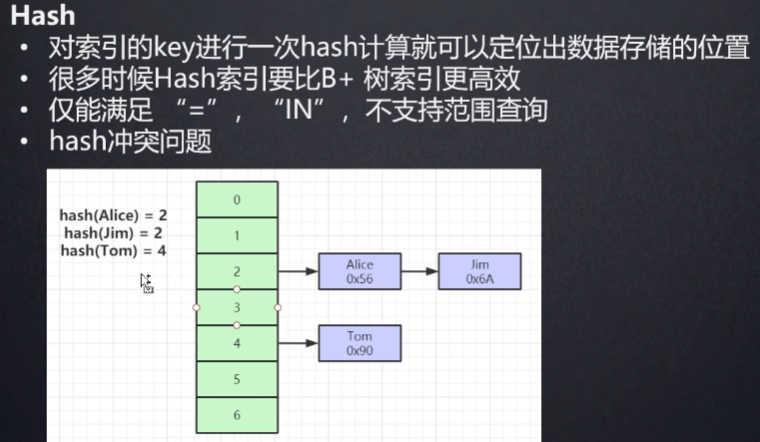
支持Hash索引
表锁
MySQL过程中临时表就是Memory表。
如果中间结果大大超出了Memory表的限制,或者含有BLOB或者TEXT字段,则临时表会转换成MyISAM表。
适用:需要快速的访问数据,并且这些数据不会被修改,重启以后丢失也没有关系
MySQL索引
B+树:
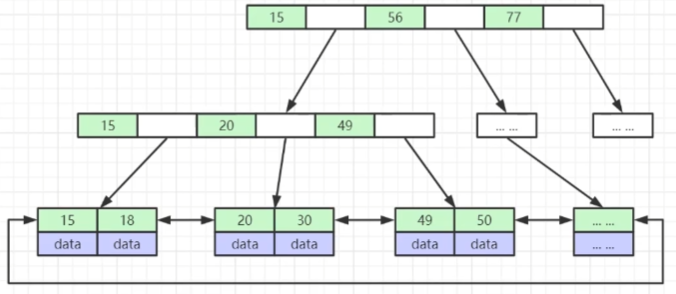
HASH:
- 查询效率高 不支持范围查询
聚族索引(索引数据放一起)
- innodb主键是这个索引结构
非聚族索引(叶子放ID没有数据)
- innodb非主键的索引,叶子存的主键ID,查其它数据时需要用这个ID回表,myisam也是这个索引(叶子存的地址,去读硬盘)
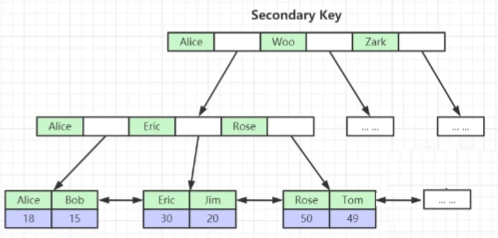
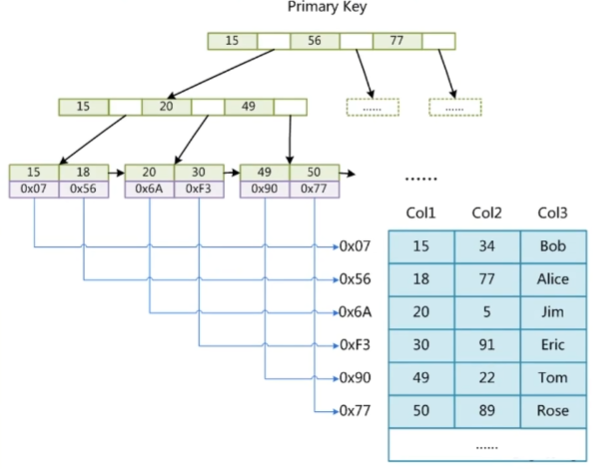
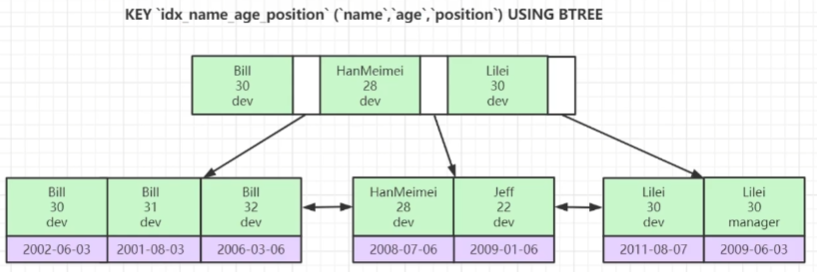
组合索引
- 最左排序
MySQL事务
ACID
- 原子性:一个事务要么成功要么失败。实现原理:undo log,innodb执行sql后会生成相反的sql到undo log。
- 一致性:事务执行前后,数据保持一致。实现原理:最终目标,由业务保证
- 持久性:一个事务一旦提交,它对数据库的改变是永久性的。实现原理:redo log,事务提交先写到redo log -> os log -> 写到磁盘
- 隔离性:不同事务之间不能相互影响。实现原理:写-写:通过锁实现,写-读:MVCC实现
并发事务问题
- 数据丢失: A事务提交或回滚,覆盖B事务数据,多个事务同时操作一行记录
- 脏读: 读到未提交事务数据
- 不可重复读:(一个事务范围内相同查询返回不同结果)
- 幻读:读到已提交的插入数据
隔离级别
- 读未提交:可能读到其它未提交的事务数据,存在脏读
- 读已提交:解决脏读,MVCC实现,每次select都生成最新的read view,根据版本号读取可见的已提交的版本数据
- 可重复读:解决不可重复读,MVCC实现,一个事务第一次select生成read view,后面相同的select使用同一个read view(当前事务update数据后,会重新生成readView)
- 串行:数据读写都会加锁。
锁
表锁 页锁 行锁
- 表锁:对当前操作的整张表加锁(对select快照读也有效)
- lock table xxx read,只读方式锁住xxx,该表只能被select,不能被修改。如果在lock时,该表上存在事务,则lock语句挂起,直到事务结束。多个会话可以同时对表执行该操作
- lock table xxx write,读写方式锁住xxx,lock table的会话可以对表xxx做修改及查询等操作,而其他会话不能对该表做任何操作,包括select也要被阻塞。
lock tables user write; // 读写方式锁住user表,其它事务不能读或写这个表 insert into user valuse ()...; unlock tables; // 解锁 - 页锁:页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。BDB支持页级锁
- 行锁:锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。分为共享锁,排他锁
共享锁(读锁S) 排他锁(写锁X)
以下读都是 当前读(select … for update,增 删 改 都是当前读) ,快照读不会上锁(select …)
- 读锁:读锁之间互不影响,读锁和写锁会阻塞
select * from user where name = 1 lock in share mode; // 给记录加读锁 - 写锁:
select * from user where name = 1 for update; // 给记录加写锁 update insert delete 默认加写锁
意向共享锁(IS)和意向排他锁(IX)
一个事务加了行锁之后,会加一个表意向锁。这样另一个事务想加表锁时就会直接判断,是否存在意向锁。不然还要一行一行遍历。
当然一个事务加了行排他锁,就加表意向排他锁,行共享锁就加意向共享锁。只有意向共享锁和表共享锁兼容,其它都阻塞
间隙锁(Gap Lock)
间隙锁:(RR级别下)一个在索引记录之间的间隙上的锁(防止其它事务插入,解决幻读)
间隙锁和行锁合称next-key lock(临键锁,锁定一个范围,并且锁定记录本身),每个next-key lock 是前开后闭区间
对于唯一索引的情况下,会优化成行锁,也就是不会锁范围间隙
对于非唯一索引就加间隙锁也可以说next-key lock(按数据间隙划分区间,包含where语句条件的整个区间都会加间隙锁)
对于非索引字段进行update,delete或select … for update操作,代价极高。所有记录上锁,以及所有间隔的锁。
id age phone
2 6 443
3 10 466
8 11 555
30 20 666上面主键id间隙区间就有(-∞,2)(3,8)(8,30)(30,+∞)
age普通二级索引间隙区间(0,6)(6,10)(11,20)(20,+∞)
select * from user where id = 2 for update; // 行锁
select * from user where id > 0 and id < 8 for update; // (-∞,2)(3,8)两个区间包含条件,加临键锁(-∞,8]都加了锁
select * from user where age = 1 for update; // age为普通索引,上间隙锁 1经过(0,6)
select * from user where age > 10 and age < 15 for update; // [10,20]加锁
二级非唯一索引排序会带着主键一起排,比如:(age, id)悲观锁,乐观锁
mysql中加的锁都是悲观锁,乐观锁需要手动实现(版本号,或时间戳实现)
- 悲观锁
BEGIN; SELECT gold FROM user WHERE id = 1 FOR UPDATE; // 加行排他锁,没提交事务前,其它事务无法修改这一行 UPDATE user SET gold = gold - 100 WHERE id = 1; COMMIT; - 乐观锁
begin; // 基本逻辑是这样 select version from user where id = 1; //先查询出版本 update user set gold = gold - 100, version = version + 1 where id = 1 and version = #{version}; // 筛选时判断版本,更新时版本号+1 COMMIT;
MVCC
多版本并发控制
提高数据库并发性能,更优处理读-写冲突,做到不加锁,非阻塞并发读
快照读:普通select,利用MVCC机制,读取版本数据,不阻塞。
当前读:select lock in share mode,select for update,update,insert,delete,加锁,保证读的是最新的数据。
undo log
innodb顺序存储在磁盘的日志,每次更新数据后,产生undo log,可用于回滚数据。(begin并不是事务起点,执行到第一次更新操作的时候才是事务起点,产生事务ID和版本)
trx_id:事务ID(每个事务依次递增)
roll_pointer:上个版本的地址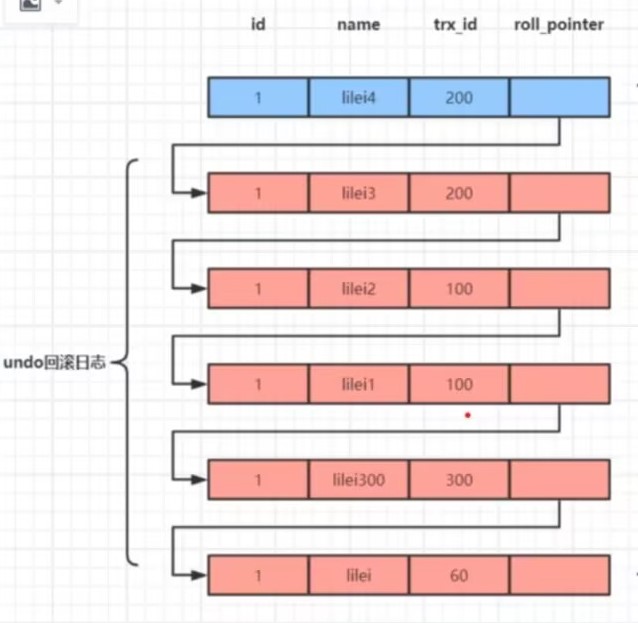
readView
readView:保存事务ID的list列表,记录当前事务执行时,还有哪些活跃的事务
包含以下数据:
m_ids:当前活跃事务ID列表;
min_trx_id:m_ids列表中最小的事务ID
max_trx_id:已创建的最大事务ID
creator_trx_id:这个开启的事务的 id。提交读隔离级别:每次select(快照读)都会重新生成readView
可重复读隔离级别:事务开始第一次select生成readView,后面的select以第一次的readView为准(不同select语句也是)
快照读选择版本逻辑
select根据readView的属性,从undo log判断符合条件的版本作为结果
从最新的版本开始依次判断
比对规则(依次比较):
1. 版本trx_id < min_trx_id:说明该版本已经提交了,数据可见
2. 版本trx_id > max_trx_id:说明该版本是将来启动的事务生成的,数据不可见
3. 判断版本trx_id是否存在m_ids数组:
a. 存在,这个版本由活跃的事务创建,数据不可见(如果版本trx_id = 自身的事务ID,数据可见)
b. 不存在,这个版本由已提交的事务创建,数据可见日志
bin log归档日志
bin log在server层,所有存储引擎共有
bin log是逻辑日志,记录一条sql的原始逻辑
记录了所有的DDL和DML语句(除了数据查询语句select)
bin log不限大小,追加写入,不会覆盖以前的日志
用于数据恢复,主从复制
开启配置:
my.cnf配置文件
# 开启 Binlog 并写明存放日志的位置
log_bin = /usr/local/mysql/log/bin-log
# 指定索引文件的位置
log_bin_index = /usr/local/mysql/log/mysql-bin.index
#删除超出这个变量保留期之前的全部日志被删除
expire_logs_days = 7
# 指定一个集群内的 MySQL 服务器 ID,如果做数据库集群那么必须全局唯一,一般来说不推荐 指定 server_id 等于 1。
server_id = 1
# Binlog 的日志模式(三种)
# STATEMENT:记录的是数据库上执行的原生SQL语句
# ROW:记录数据表的行是怎样被修改的。
# MIXED:混合模式,在一些特定的情况下自动从 STATEMENT 格式切换到 ROW 格式。
binlog_format = ROW
#控制对哪些数据库进行收集,如果不配置,默认全部数据库都会进行日志收集
binlog_do_db=testwindows my.ini配置文件
log_bin=mysql-bin
binlog-format=ROW
server-id=1相关命令:
sync_binlog:设置为1,每次事务都将持久化到硬盘
show master logs;查看所有binlog日志列表
flush logs:多创建一个bin-log日志(每当mysqld服务重启时,会自动执行此命令)
reset master;重置(清空)所有binlog日志
mysqlbinlog.exe --no-defaults mysql-bin.000001;查看日志
mysqlbinlog.exe --no-defaults --base64-output=decode-rows -v ../../sqldata/binlog/mysql-bin.000114 > C:\Users\1212\Desktop\binlog.txt
# mysqlbinlog.exe命令转换为可读的文件
mysqlbinlog.exe --base64-output=decode-rows -v "...\mysql-bin.000001" >mysqlbin.log;
# 恢复全部数据
mysqlbinlog --no-defaults ../mysql-bin.000001 | mysql -uroot -p test_database
# 恢复指定位置
mysqlbinlog --no-defaults ../mysql-bin.000001 --stop-position="99" --start-position="53" | mysql -uroot -p test_database
mysqlbinlog.exe --no-defaults ../../sqldata/binlog/mysql-bin.000114 --stop-position="511" --start-position="291" | mysql -uroot -proot
# 其它参数
--start-datetime="2016-9-25 22:01:08" 起始时间点
--stop-datetime="2019-9-25 22:09:46" 结束时间点
--database=ops指定只恢复ops数据库(一台主机上往往有多个数据库,只限本地log日志)redo log重做日志
redo log是innodb独有日志,记录数据库所有修改记录,主要用于恢复mysql缓存数据(buffer pool缓存池)
mysql执行的一系列修改操作不会第一时间更新磁盘,而是更新缓存池和新增redo log,如果宕机,重启mysql会利用redo log恢复缓存池的数据
redo log写的流程:redo log buffer -> os buffer -> redo log磁盘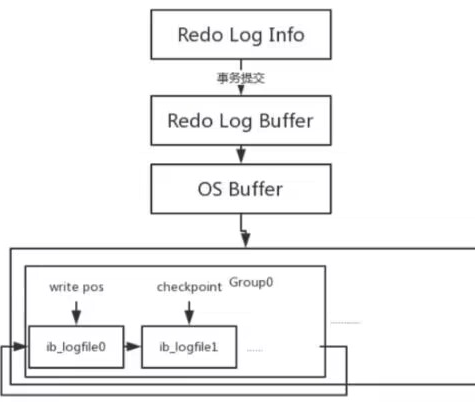
其中有三种方式写入磁盘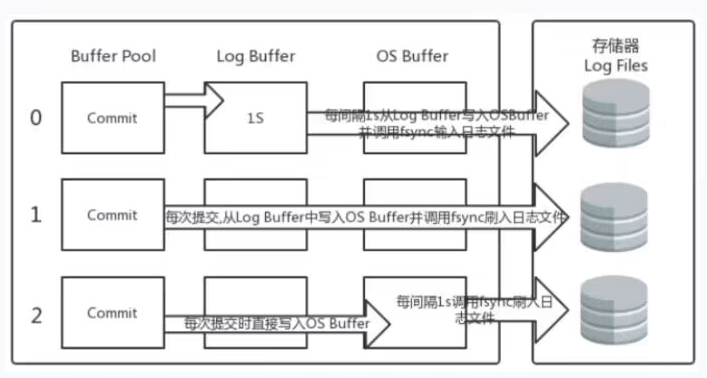
Innodb存储引擎工作流程
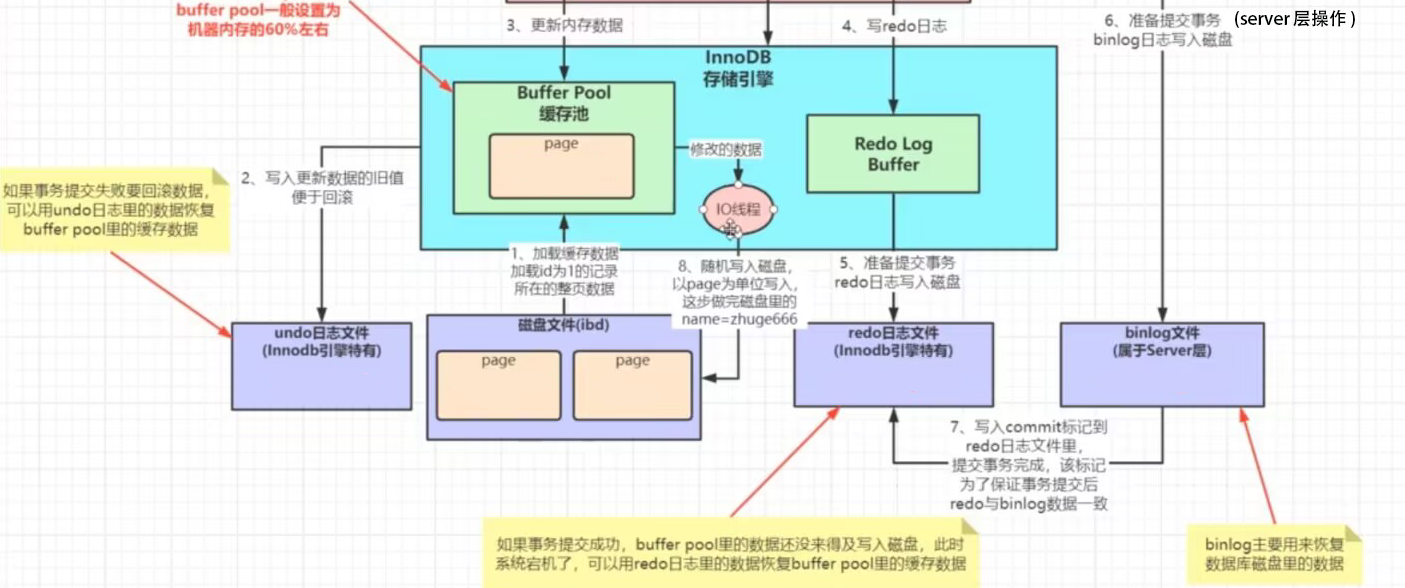
其中写redolog磁盘是顺序IO,性能很快。与之相比,修改数据进行磁盘IO是随机IO,性能很差。

