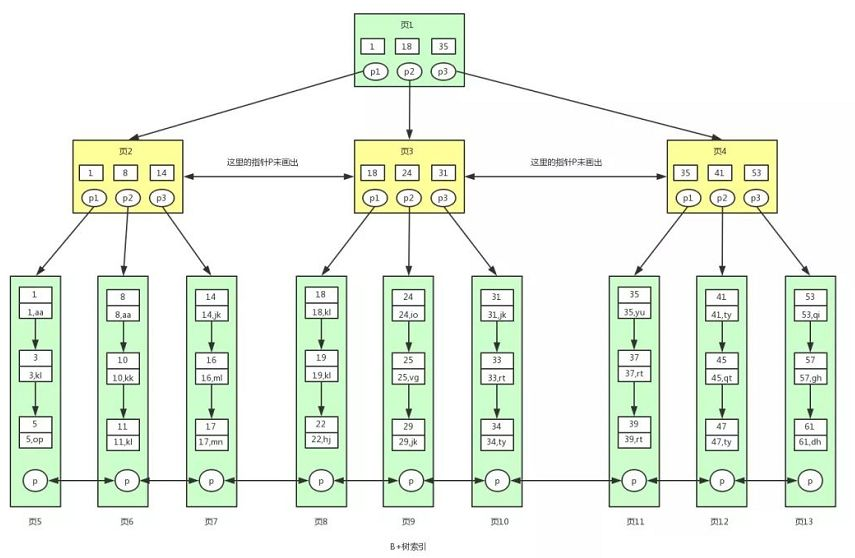
InnoDB的B+树
B+树
特性
在叶子节点一层,所有记录的主键按照从小到大的顺序排列,并且形成了一个双向链表。叶子节点的每一个Key指向一条记录。
非叶子节点取的是叶子节点里面Key的最小值。这意味着所有 非叶子节点的Key都是冗余的叶子节点。同一层的非叶子节点也互相串 联,形成了一个双向链表。
逻辑结构
基于B+树的特性,会发现对于offset这种特性,其实是用不到索引的。比如每页显示10条数据,要展示第101页,通常会写成select xxx where xxx limit 1000, 10,从offset = 1000的位置开始取10条。 虽然只取了10条数据,但实际上数据库要把前面的1000条数据都遍 历才能知道 offset =1000的位置在哪。对于这种情况,合理的办法是不 要用offset,而是把offset = 1000的位置换算成某个max_id,然后用where 语句实现
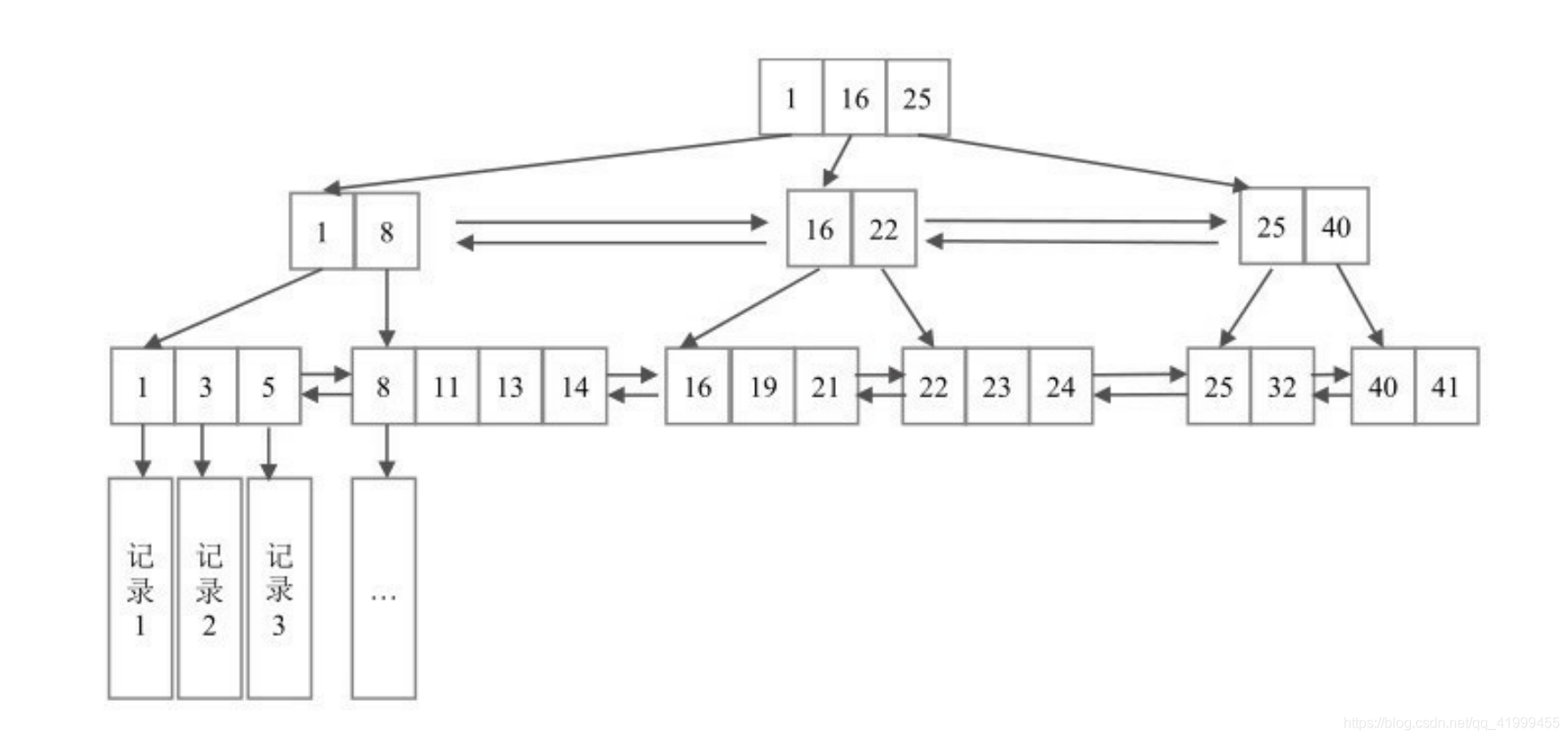
物理结构
InnoDB默认定义的块大小是16KB,通过innodb_page_size参数指定
无论叶子节点,还是非叶子节点,都会装在 Page里
如果用来装非叶子节点,一个Page大概 可以装1000个Key(16K,假设Key是64位整数,8个字节,再加上各种 其他字段),意味着B+树有1000个分叉;如果用来装叶子节点,一个 Page大概可以装200条记录(记录和索引放在一起存储,假设一条记录大概100个字节)
三层B+:
第二层1000200
第三层10001000200 = 2亿条记录,总容量16K1000*1000 = 16GB

B+树演变过程
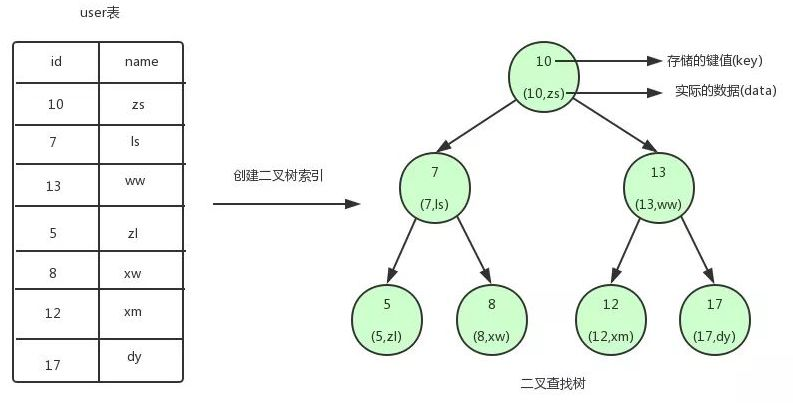
最早的二叉查找树
二叉树的特点是左侧的子节点的值都比父节点小,右侧的子节点的值都比父节点大。
这样查找从顶节点开始查找,这样不会超过数的高度的次数,就能查找到指定的值,效率比全表扫描是要高。
平衡二叉树
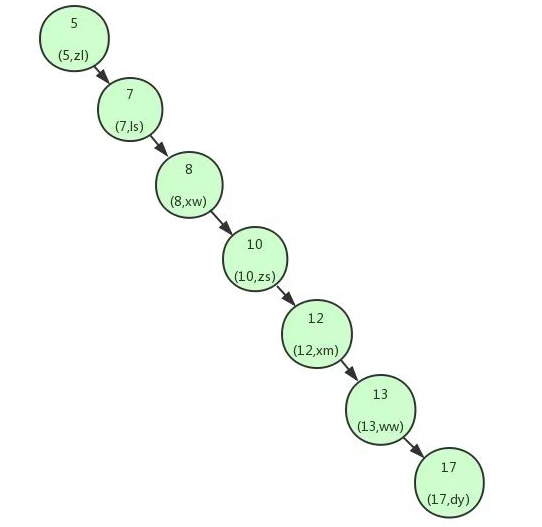
如果id字段里的值是有顺序的,可能就会生成下面这样的二叉树
导致这种情况的原因是树的不平衡,可以改进为在节点插入的过程中,保持二叉树的平衡,即每个节点的左右子树的高度差不能超过1。
B树
平衡二叉树每个节点只存储一个键值,当数据量特别的大的时候,树的高度也很高
从磁盘读取数据时是每次读取一个页的数据,如果每次读取只读取一个键值,也是对磁盘的浪费
所以B树的改进:
每个节点(页)存储了更多的键值(key)和数据(data)
每个节点拥有更多的子节点,并不只是二叉树了。
B+树
B树也有缺点:
- 每个页里面存储了key和data,data占了大量数据,每个页大小是固定,导致一页只能放少量的key
- 数据不是按顺序存储的,当范围查找、排序查找、去重查找的时候,需要读取多个级别的多个页,效率比较低。
B+树的改进:- 非叶子节点只存key不存数据,所有数据都存在叶子节点,所以数据是按顺序存储的,使得范围查找、排序查找更加方便。
- B+树的页之间用双向链表连接,数据间用单项链表链接
参考:https://blog.csdn.net/qq_41999455/article/details/106138619