SQL分页造成的性能问题
SQL执行的流程
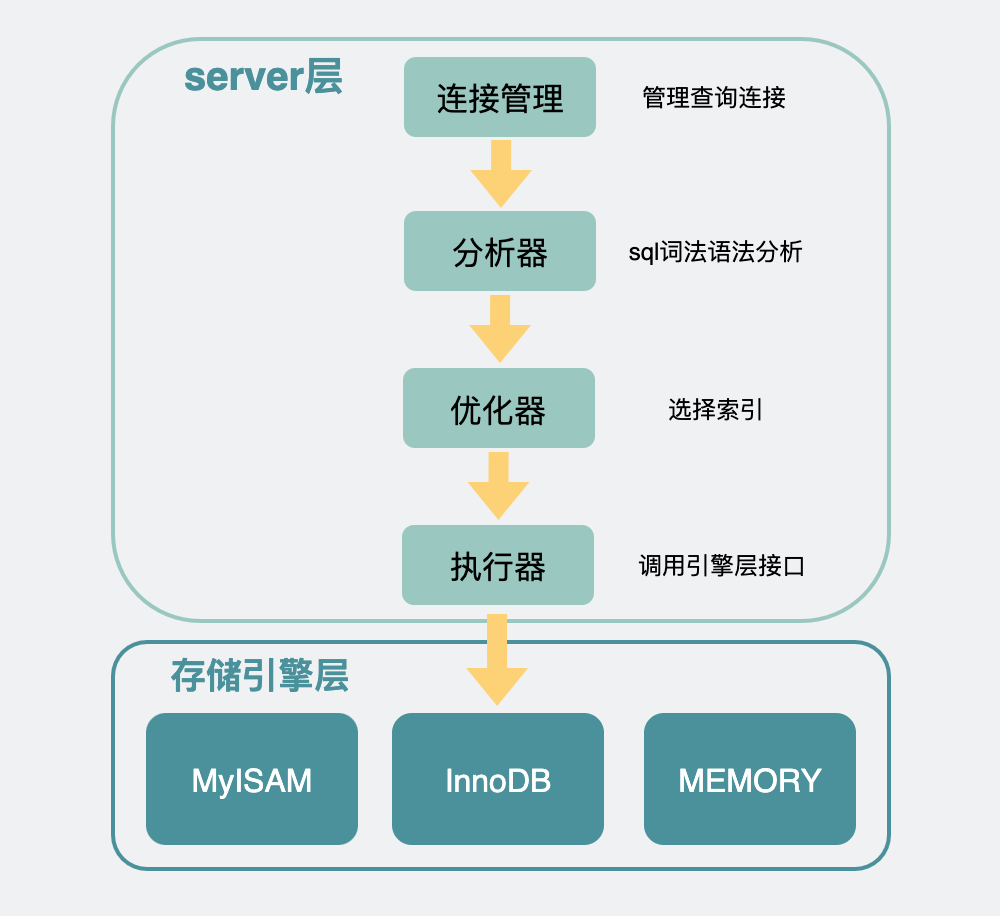
mysql内部分为server层和存储引擎层。
执行器可以通过调用存储引擎提供的接口,将一行行数据取出,当这些数据完全符合要求(比如满足其他where条件),则会放到结果集中,最后返回给调用mysql的客户端
怎么拿数据
主键索引本质是一棵B+树,它是放在innodb中的一个数据结构。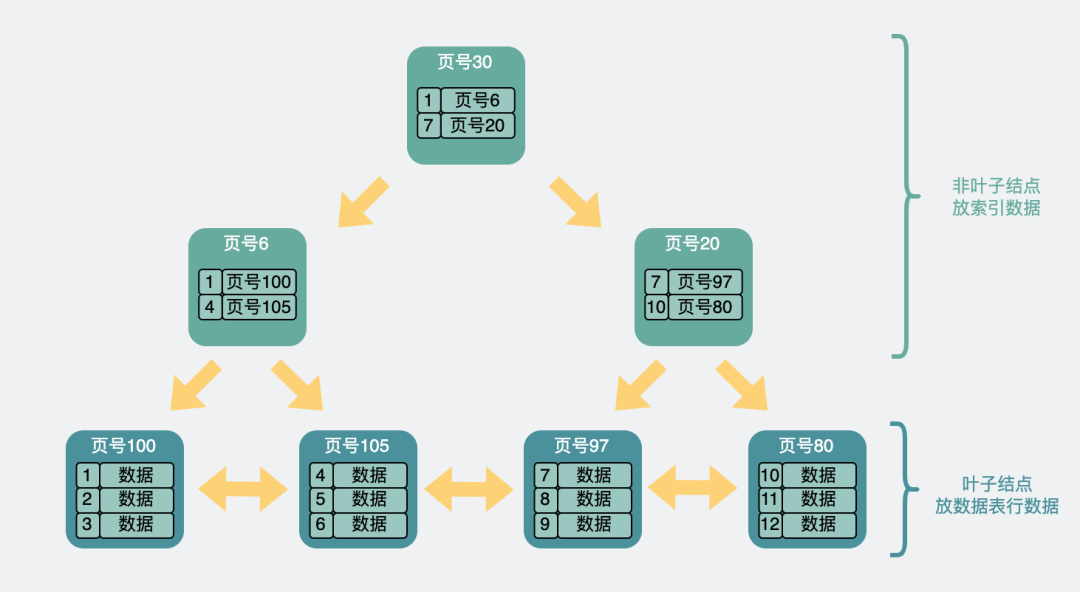
如果是主键索引,它的叶子节点会存放完整的行数据信息。
如果是非主键索引,那它的叶子节点则会存放主键,如果想获得行数据信息,则需要再跑到主键索引去拿一次数据,这叫回表。
select * from page where user_name = “小白10”;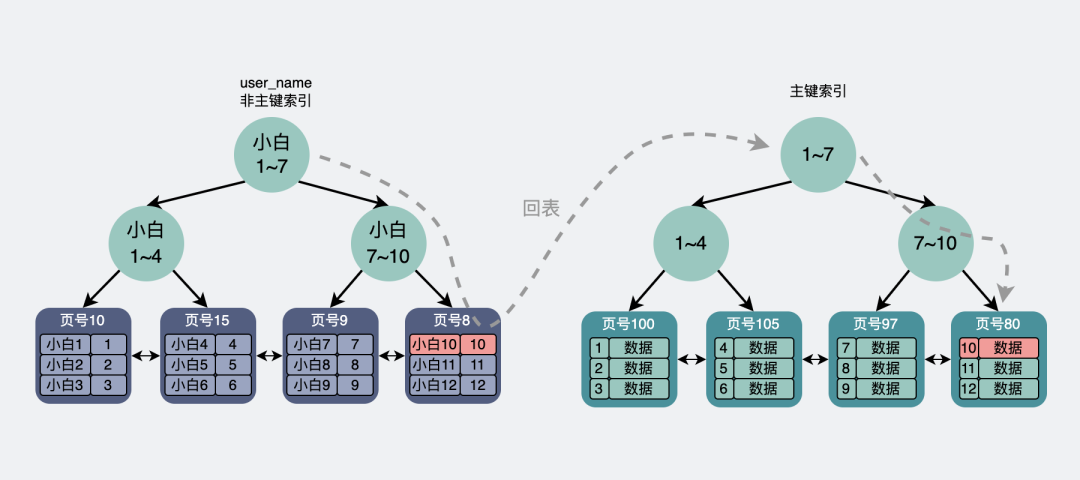
分页查询
下面按主键索引查询
select * from page order by id limit 6000000, 10;server层会调用innodb的接口,在innodb里的主键索引中获取到第0到(6000000 + 10)条完整行数据,返回给server层之后根据offset的值挨个抛弃,最后只留下最后面的size条,也就是10条数据,放到server层的结果集中,返回给客户端。
优化:
select * from page where id >=(select id from page order by id limit 6000000, 1) order by id limit 10;如果是以下sql(深度分页)
select * from page order by user_name limit 6000000, 10;非主键索引的600w次回表
当limit offset过大时,非主键索引查询非常容易变成全表扫描。是真·性能杀手
优化:
select * from page t1, (select id from page order by user_name limit 6000000, 100) t2 WHERE t1.id = t2.id;只拿主键id,不需要回表
再用这100个id去跟t1表做id匹配
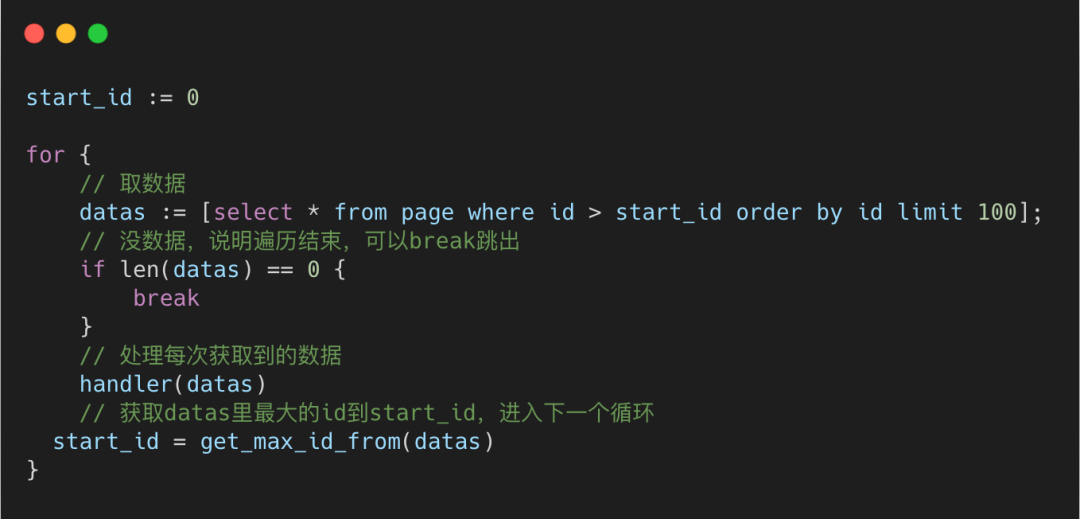
避免深度分页
如果想取出全表的数据,数据较大时,避免使用分页,造成深度分页
可以将所有的数据根据id主键进行排序,然后分批次取,将当前批次的最大id作为下次筛选的条件进行查询。