Java线程
concurrent包的实现
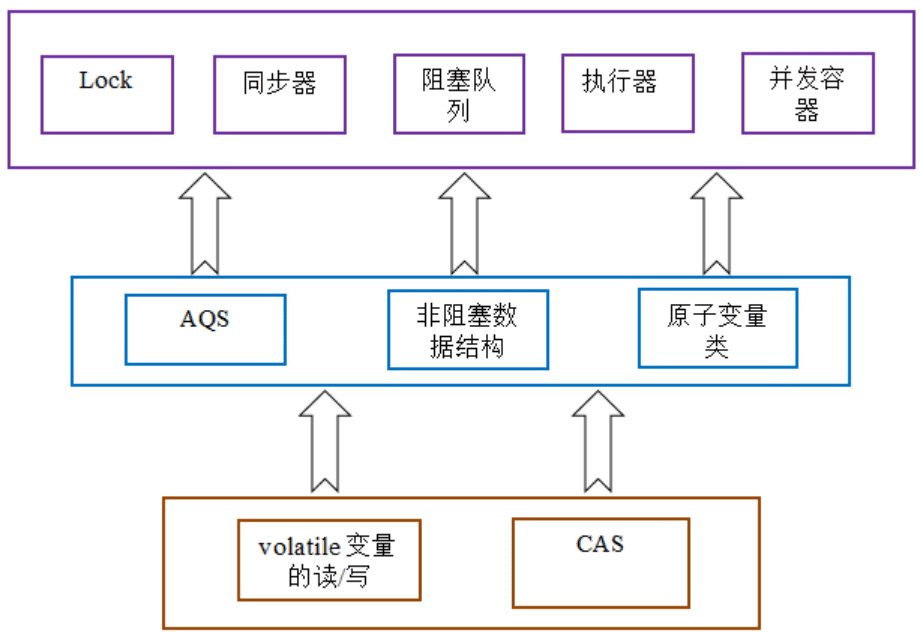
由于Java的CAS同时具有 volatile 读和volatile写的内存语义,因此Java线程之间的通信现在有了下⾯四种⽅式:
- A线程写volatile变量,随后B线程读这个volatile变量。
- A线程写volatile变量,随后B线程⽤CAS更新这个volatile变量。
- A线程⽤CAS更新⼀个volatile变量,随后B线程⽤CAS更新这个volatile变量。
- A线程⽤CAS更新⼀个volatile变量,随后B线程读这个volatile变量。
Java的CAS会使⽤现代处理器上提供的⾼效机器级别原⼦指令,这些原⼦指令以原⼦⽅式对内存执⾏读- 改-写操作,这是在多处理器中实现同步的关键
同时,volatile变量的读/写和CAS可以实现线程之间的通信。把这些特性整合在 ⼀起,就形成了整个concurrent包得以实现的基⽯。
通用化的实现模式:
- ⾸先,声明共享变量为volatile;
- 然后,使⽤CAS的原⼦条件更新来实现线程之间的同步;
- 同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信。
AQS,非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些concurrent包中的基础类都是使⽤这种模式来实现的,⽽concurrent包中的⾼层类⼜是依赖于这些基础类来实现的。从整体来看,concurrent包的实现示意图如下:
Java线程池详解
线程的创建和销毁,都涉及到系统调⽤,⽐较消耗系统资源,那么有没有⼀种办法使得线程可以复⽤,就 是执⾏完⼀个任务,并不被销毁,⽽是可以继续执⾏其他的任务?所以就引⼊了线程池技术,避免频繁的 线程创建和销毁。
在Java中有⼀个Executors⼯具类,可以为我们创建⼀个线程池,其本质就是new了⼀个 ThreadPoolExecutor对象
ThreadPoolExecutor类
java.uitl.concurrent.ThreadPoolExecutor类是线程池中最核⼼的⼀个类,因此如果要透彻地了解Java中 的线程池,必须先了解这个类。
ThreadPoolExecutor类中提供了四个构造⽅法:public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler); } public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, defaultHandler); } public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), handler); } public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }ThreadPoolExecutor继承了AbstractExecutorService类,并提供了四个构造 器,事实上,通过观察每个构造器的源码具体实现,发现前⾯三个构造器都是调⽤的第四个构造器进⾏的 初始化⼯作
构造器中各个参数的含义:
- corePoolSize:核⼼池的⼤⼩,这个参数跟后⾯讲述的线程池的实现原理有⾮常⼤的关系。在创建了 线程池后,默认情况下,线程池中并没有任何线程,⽽是等待有任务到来才创建线程去执⾏任务,除⾮ 调⽤了prestartAllCoreThreads()或者prestartCoreThread()⽅法,从这2个⽅法的名字就可以看出, 是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者⼀个线程。默认情况 下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建⼀个线程去执⾏任务,当 线程池中的线程数⽬达到corePoolSize后,就会把到达的任务放到缓存队列当中;
- maximumPoolSize:线程池最⼤线程数,这个参数也是⼀个⾮常重要的参数,它表示在线程池中最多 能创建多少个线程;
- keepAliveTime:表示线程没有任务执⾏时最多保持多久时间会终⽌。默认情况下,只有当线程池中的 线程数⼤于corePoolSize时,keepAliveTime才会起作⽤,直到线程池中的线程数不⼤于 corePoolSize,即当线程池中的线程数⼤于corePoolSize时,如果⼀个线程空闲的时间达到 keepAliveTime,则会终⽌,直到线程池中的线程数不超过corePoolSize。但是如果调⽤了 allowCoreThreadTimeOut(boolean)⽅法,在线程池中的线程数不⼤于corePoolSize时, keepAliveTime参数也会起作⽤,直到线程池中的线程数为0;
- unit:参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:
TimeUnit.DAYS; //天 TimeUnit.HOURS; //⼩时 TimeUnit.MINUTES; //分钟 TimeUnit.SECONDS; //秒 TimeUnit.MILLISECONDS; //毫秒 TimeUnit.MICROSECONDS; //微妙 TimeUnit.NANOSECONDS; //纳秒- workQueue:⼀个阻塞队列,用来存储等待执⾏的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,⼀般来说,这里的阻塞队列有以下⼏种选择:
- ArrayBlockingQueue;
- LinkedBlockingQueue;
- SynchronousQueue;
- ArrayBlockingQueue和PriorityBlockingQueue使⽤较少,⼀般使⽤LinkedBlockingQueue和 Synchronous。线程池的排队策略与BlockingQueue有关。
- threadFactory:线程⼯⼚,主要⽤来创建线程;
- handler:表示当拒绝处理任务时的策略,有以下四种取值:
- ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionExcepti on异常
- ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前⾯的任务,然后重新尝 试执⾏任务(重复此过程)
- ThreadPoolExecutor.CallerRunsPolicy:由调⽤线程处理该任务
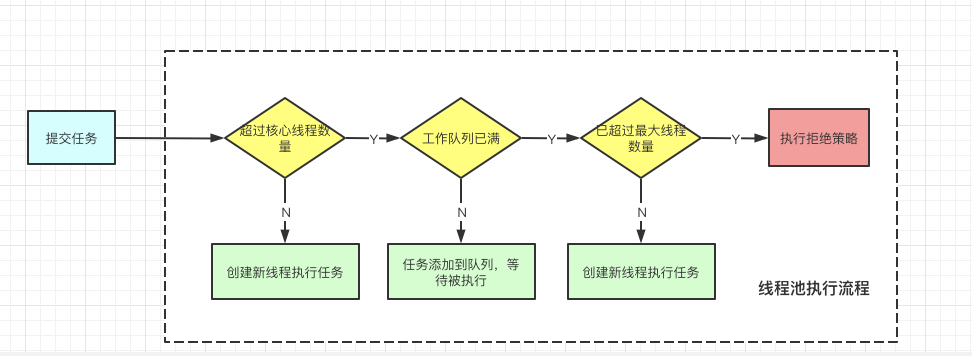
线程池的执⾏流程:
任务被提交到线程池,会先判断当前线程数量是否⼩于corePoolSize,如果⼩于则创建线程来执⾏提交的 任务,否则将任务放⼊workQueue队列,如果workQueue满了,则判断当前线程数量是否⼩于 maximumPoolSize,如果⼩于则创建线程执⾏任务,否则就会调⽤handler,以表示线程池拒绝接收任务。
线程池的execute方法:int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) reject(command);判断当前活跃线程数是否⼩于corePoolSize,如果⼩于,则调⽤addWorker创建线程执⾏任务
如果不⼩于corePoolSize,则将任务添加到workQueue队列。
如果放⼊workQueue失败,则创建线程执⾏任务,如果这时创建线程失败(当前线程数不⼩于 maximumPoolSize时),就会调⽤reject(内部调⽤handler)拒绝接受任务。
addWorker方法:private boolean addWorker(Runnable firstTask, boolean core) { retry: for (;;) { int c = ctl.get(); int rs = runStateOf(c); // Check if queue empty only if necessary. if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) return false; for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); // Re-read ctl if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } } boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { w = new Worker(firstTask); final Thread t = w.thread; if (t != null) { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int rs = runStateOf(ctl.get()); if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) { if (t.isAlive()) // precheck that t is startable throw new IllegalThreadStateException(); workers.add(w); int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); } if (workerAdded) { t.start(); workerStarted = true; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }wc >= (core ? corePoolSize : maximumPoolSize)) return false; //这块代码是在创建非核心线程时,即core等于false。 //判断当前线程数是否大于等于maximumPoolSize, 如果大于等于则返回false, //即上边说到的addWorker(command, false)中创建线程失败的情况。w = new Worker(firstTask); final Thread t = w.thread; //创建Worker对象,同时也会实例化⼀个Thread对象。 t.start(); //启动这个线程
再看看Worker的实现:Worker(Runnable firstTask) { setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); } public void run() { runWorker(this); }可以看到在创建Worker时会调⽤threadFactory来创建⼀个线程。上边的t.start()中启动⼀个线程就会触发 Worker的run⽅法被线程调⽤。
runWorker⽅法的逻辑:try { while (task != null || (task = getTask()) != null) { w.lock(); // If pool is stopping, ensure thread is interrupted; // if not, ensure thread is not interrupted. This // requires a recheck in second case to deal with // shutdownNow race while clearing interrupt if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { beforeExecute(wt, task); Throwable thrown = null; try { task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error(x); } finally { afterExecute(task, thrown); } } finally { task = null; w.completedTasks++; w.unlock(); } }线程调⽤runWoker,会while循环调⽤getTask⽅法从workerQueue⾥读取任务,然后执⾏任务。只要 getTask⽅法不返回null,此线程就不会退出。
看getTask⽅法实现:private Runnable getTask() { boolean timedOut = false; // Did the last poll() time out? for (;;) { int c = ctl.get(); int rs = runStateOf(c); // Check if queue empty only if necessary. if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) { decrementWorkerCount(); return null; } int wc = workerCountOf(c); // Are workers subject to culling? boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) { if (compareAndDecrementWorkerCount(c)) return null; continue; } try { Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); if (r != null) return r; timedOut = true; } catch (InterruptedException retry) { timedOut = false; } } }boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; //allowCoreThreadTimeOut,这个变量默认值是false。wc>corePoolSize则是判断当前线 程数是否⼤于corePoolSize。 Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); //如果当前线程数⼤于corePoolSize,则会调⽤workQueue的poll⽅法获取任务,超时时间是 keepAliveTime。 //如果超过keepAliveTime时⻓,poll返回了null,上边提到的while循序就会退出,线程也就执⾏完了。 //如果当前线程数⼩于corePoolSize,则会调⽤workQueue的take⽅法阻塞在当前。
Synchronized原理和优化
Synchronized是Java中解决并发问题的⼀种最常⽤的⽅法,也是最简单的⼀种⽅法。Synchronized的作用主要有三个:
- 确保线程互斥的访问同步代码
- 保证共享变量的修改能够及时可⻅
- 有效解决 重排序问题。
Synchronized如何实现同步
每个对象有⼀个监视器锁(monitor)。当monitor被占⽤时就会处于锁定状态,线程执⾏monitorenter指 令时尝试获取monitor的所有权,过程如下:
- 如果monitor的进⼊数为0,则该线程进⼊monitor,然后将进⼊数设置为1,该线程即为monitor的所有者
- 如果线程已经占有该monitor,只是重新进⼊,则进⼊monitor的进⼊数加1.
- 如果其他线程已经占⽤了monitor,则该线程进⼊阻塞状态,直到monitor的进⼊数为0,再重新尝试获 取monitor的所有权。
执⾏monitorexit的线程必须是objectref所对应的monitor的所有者
指令执⾏时,monitor的进⼊数减1,如果减1后进⼊数为0,那线程退出monitor,不再是这个monitor的所 有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
Synchronized的语义底层是通过 ⼀个monitor的对象来完成,其实wait/notify等⽅法也依赖于monitor对象,这就是为什么只有在同步的块 或者方法中才能调⽤wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的 原因。同步⽅法:
方法的同步并没有通过指令monitorenter和monitorexit来完成(理论上其实也可以 通过这两条指令来实现),不过相对于普通⽅法,其常量池中多了ACC_SYNCHRONIZED标示符。JVM就 是根据该标示符来实现方法的同步的:当方法调用时,调用指令将会检查⽅法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执⾏线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同⼀个monitor对象。 其实本质上没 有区别,只是⽅法的同步是⼀种隐式的⽅式来实现,⽆需通过字节码来完成。重量级锁
Synchronized是通过对象内部的⼀个叫做监视器锁(monitor)来实现的。但是监视器锁本质⼜是依赖于 底层的操作系统的Mutex Lock来实现的。⽽操作系统实现线程之间的切换这就需要从⽤户态转换到核⼼态,这个成本⾮常⾼,状态之间的转换需要相对⽐较⻓的时间,这就是为什么Synchronized效率低的原 因。
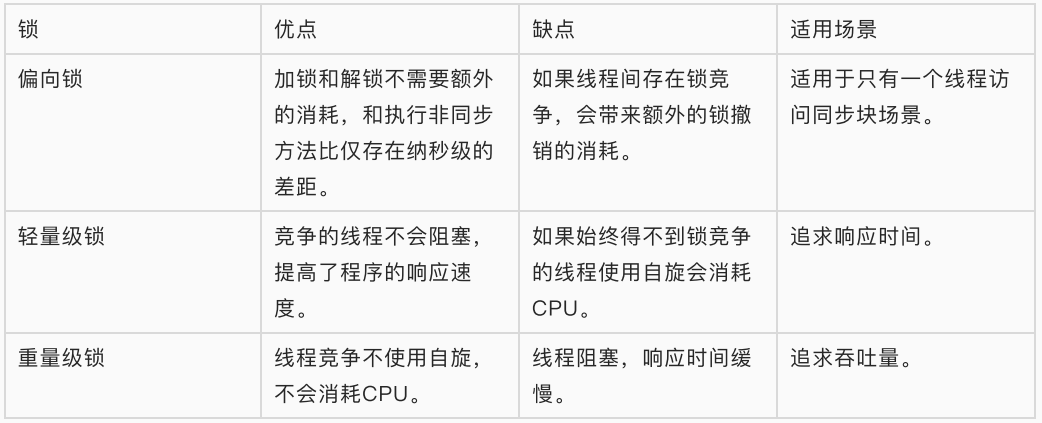
依赖于操作系统Mutex Lock所实现的锁我们称之为“重量级锁”。
JDK1.6以后,为了减少获得锁和释放锁所带来 的性能消耗,提高性能,引入了“轻量级锁”和“偏向锁”。轻量级锁
“轻量级”是相对于使⽤操作系统互斥量来实现的传统锁⽽⾔的。但是,⾸先需要强调⼀点的是,轻量级锁 并不是⽤来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使⽤产⽣的性 能消耗。在解释轻量级锁的执⾏过程之前,先明⽩⼀点,轻量级锁所适应的场景是线程交替执⾏同步块的 情况,如果存在同⼀时间访问同⼀锁的情况,就会导致轻量级锁膨胀为重量级锁。偏向锁
引⼊偏向锁是为了在⽆多线程竞争的情况下尽量减少不必要的轻量级锁执⾏路径,因为轻量级锁的获取及 释放依赖多次CAS原⼦指令,⽽偏向锁只需要在置换ThreadID的时候依赖⼀次CAS原⼦指令(由于⼀旦出 现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须⼩于节省下来的CAS原⼦ 指令的性能消耗)。上⾯说过,轻量级锁是为了在线程交替执⾏同步块时提⾼性能,⽽偏向锁则是在只有 ⼀个线程执⾏同步块时进⼀步提⾼性能。比较上面的三种锁:
其他优化
适应性自旋(Adaptive Spinning):
从轻量级锁获取的流程中我们知道,当线程在获取轻量级锁的过程中执行CAS操作失败时,是要通过自旋来获取重量级锁的。问题在于,自旋是需要消耗CPU的,如果⼀直获取不到锁的话,那该线程就⼀直处在⾃旋状态,白白浪费CPU资源。解决这个问题最简单的办法就是 指定自旋的次数,例如让其循环10次,如果还没获取到锁就进入阻塞状态。但是JDK采⽤了更聪明的⽅式 ——适应性自旋,简单来说就是线程如果自旋成功了,则下次自旋的次数会更多,如果自旋失败了,则自旋的次数就会减少。
锁粗化(Lock Coarsening):
锁粗化的概念应该⽐较好理解,就是将多次连接在⼀起的加锁、解锁 操作合并为⼀次,将多个连续的锁扩展成⼀个范围更⼤的锁。举个例⼦:public class StringBufferTest { StringBuffer stringBuffer = new StringBuffer(); public void append(){ stringBuffer.append("a"); stringBuffer.append("b"); } }这⾥每次调⽤stringBuffer.append⽅法都需要加锁和解锁,如果虚拟机检测到有⼀系列连串的对同⼀个对象加锁和解锁操作,就会将其合并成⼀次范围更⼤的加锁和解锁操作,即在第⼀次append⽅法时进⾏加锁,最后⼀次append⽅法结束后进⾏解锁。
锁消除(Lock Elimination):
锁消除即删除不必要的加锁操作。根据代码逃逸技术,如果判断到⼀段代码中,堆上的数据不会逃逸出当前线程,那么可以认为这段代码是线程安全的,不必要加锁。
ThreadLocal
- Synchronized⽤于线程间的数据共享,⽽ThreadLocal则⽤于线 程间的数据隔离。所以ThreadLocal的应⽤场合,最适合的是按线程多实例(每个线程对应⼀个实例)的 对象的访问,并且这个对象很多地⽅都要⽤到。
- Thread有个TheadLocalMap类型的属性,叫做threadLocals,该属性⽤ 来保存该线程本地变量。这样每个线程都有⾃⼰的数据,就做到了不同线程间数据的隔离,保证了数据安 全。
- 当使⽤ThreadLocal维护变量时,ThreadLocal为每个使⽤该变量的线程提供独⽴的变量副本,所以每⼀个线程都可以独⽴地改变⾃⼰的副本,⽽不会影响其它线程所对应的副本。
- 从线程的⻆度看,⽬标变量就象是线程的本地变量,这也是类名中“Local”所要表达的意思。
原理
- ThreadLocal,连接ThreadLocalMap和Thread。来处理Thread的TheadLocalMap属性,包括init初始 化属性赋值、get对应的变量,set设置变量等。通过当前线程,获取线程上的ThreadLocalMap属性,对 数据进⾏get、set等操作。
- ThreadLocalMap,⽤来存储数据,采⽤类似hashmap机制,存储了以threadLocal为key,需要隔离的数 据为value的Entry键值对数组结构。
- ThreadLocal,有个ThreadLocalMap类型的属性,存储的数据就放在这⼉。
ThreadLocal、ThreadLocal、Thread之间的关系
ThreadLocalMap是ThreadLocal内部类,由ThreadLocal创建,Thread有 ThreadLocal.ThreadLocalMap类型的属性
Thread同步机制的⽐较
ThreadLocal和线程同步机制相⽐有什么优势呢?
Synchronized⽤于线程间的数据共享,⽽ThreadLocal则⽤于线程间的数据隔离。
- 在同步机制中,通过对象的锁机制保证同⼀时间只有⼀个线程访问变量。这时该变量是多个线程共享的, 使⽤同步机制要求程序慎密地分析什么时候对变量进⾏读写,什么时候需要锁定某个对象,什么时候释放 对象锁等繁杂的问题,程序设计和编写难度相对较⼤。
- ThreadLocal则从另⼀个⻆度来解决多线程的并发访问。ThreadLocal会为每⼀个线程提供⼀个独⽴的 变量副本,从⽽隔离了多个线程对数据的访问冲突。因为每⼀个线程都拥有⾃⼰的变量副本,从⽽也就没 有必要对该变量进⾏同步了。ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不 安全的变量封装进ThreadLocal。
- 概括起来说,对于多线程资源共享的问题,同步机制采⽤了“以时间换空间”的⽅式,⽽ThreadLocal采⽤ 了“以空间换时间”的⽅式。前者仅提供⼀份变量,让不同的线程排队访问,⽽后者为每⼀个线程都提供了 ⼀份变量,因此可以同时访问⽽互不影响。
线程隔离的实现
在于上述叙述的ThreadLocalMap这个类。ThreadLocalMap是ThreadLocal类的⼀个静态内部 类,它实现了键值对的设置和获取(对⽐Map对象来理解),每个线程中都有⼀个独⽴的 ThreadLocalMap副本,它所存储的值,只能被当前线程读取和修改。ThreadLocal类通过操作每⼀个线 程特有的ThreadLocalMap副本,从⽽实现了变量访问在不同线程中的隔离。因为每个线程的变量都是⾃ ⼰特有的,完全不会有并发错误。还有⼀点就是,ThreadLocalMap存储的键值对中的键是this对象指向 的ThreadLocal对象,⽽值就是你所设置的对象了。
ThreadLocal是解决线程安全问题⼀个很好的思路,它通过为每个线程提供⼀个独⽴的变量副本解决了变 量并发访问的冲突问题。在很多情况下,ThreadLocal⽐直接使⽤synchronized同步机制解决线程安全问 题更简单,更⽅便,且结果程序拥有更⾼的并发性。
CAS
比较并交换,CAS 操作包含三个操作数—内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。
相对于对于synchronized这种锁机制,CAS是非阻塞算法的一种常见实现。
CAS是一种乐观锁的思想,失败了会重新尝试。
两个线程对数据修改,CAS默认不会存在阻塞,所以直接去修改它,结果发现有线程在修改,那么这个线程就放弃掉,然后重试。
wait,notify
wait/notify 必须配合 synchronized 使用,wait 方法释放锁,notify 方法不释放锁。
wait后释放锁,等待唤醒后再尝试获取锁(notify),其中wait可以设置参数(等待超时后,自动重新去获取锁)
notify()方法——随机唤醒一个wait的线程
notifyAll()方法——唤醒所有wait的线程,让这些被唤醒的线程去争抢,按争抢顺序依次执行
线程通信
volatile 关键字
volatile 关键字来实现线程间相互通信是使用共享内存的思想
让多个线程监听这个变量,当变量变化时,可以通知彼此,达到通信效果
public class TestSync {
//定义共享变量来实现通信,它需要volatile修饰,否则线程不能及时感知
static volatile boolean notice = false;
public static void main(String[] args) {
List<String> list = new ArrayList<>();
//线程A
Thread threadA = new Thread(() -> {
for (int i = 1; i <= 10; i++) {
list.add("abc");
System.out.println("线程A添加元素,此时list的size为:" + list.size());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (list.size() == 5)
notice = true;
}
});
//线程B
Thread threadB = new Thread(() -> {
while (true) {
if (notice) {
System.out.println("线程B收到通知,开始执行自己的业务...");
break;
}
}
});
//需要先启动线程B
threadB.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 再启动线程A
threadA.start();
}
}Object 类的 wait()/notify()
public class TestSync {
public static void main(String[] args) {
//定义一个锁对象
Object lock = new Object();
List<String> list = new ArrayList<>();
// 线程A
Thread threadA = new Thread(() -> {
synchronized (lock) {
for (int i = 1; i <= 10; i++) {
list.add("abc");
System.out.println("线程A添加元素,此时list的size为:" + list.size());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (list.size() == 5)
lock.notify();//唤醒B线程
}
}
});
//线程B
Thread threadB = new Thread(() -> {
while (true) {
synchronized (lock) {
if (list.size() != 5) {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程B收到通知,开始执行自己的业务...");
}
}
});
//需要先启动线程B
threadB.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//再启动线程A
threadA.start();
}
}这里notify之后并没有释放锁,走完自己的线程再释放锁
CountDownLatch
CountDownLatch允许一个或者多个线程去等待其他线程完成操作。
CountDownLatch接收一个int型参数,表示要等待的工作线程的个数。
方法:
await() 使当前线程进入同步队列进行等待,直到latch的值被减到0或者当前线程被中断,当前线程就会被唤醒。
await(long timeout, TimeUnit unit) 带超时时间的await()。
countDown() 使latch的值减1,如果减到了0,则会唤醒所有等待在这个latch上的线程。
getCount() 获得latch的数值。
public class TestSync {
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(1);
List<String> list = new ArrayList<>();
//线程A
Thread threadA = new Thread(() -> {
for (int i = 1; i <= 10; i++) {
list.add("abc");
System.out.println("线程A添加元素,此时list的size为:" + list.size());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (list.size() == 5)
countDownLatch.countDown();
}
});
//线程B
Thread threadB = new Thread(() -> {
while (true) {
if (list.size() != 5) {
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程B收到通知,开始执行自己的业务...");
break;
}
});
//需要先启动线程B
threadB.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//再启动线程A
threadA.start();
}
}ReentrantLock 结合 Condition
public class TestSync {
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Condition condition = lock.newCondition();
List<String> list = new ArrayList<>();
//线程A
Thread threadA = new Thread(() -> {
lock.lock();
for (int i = 1; i <= 10; i++) {
list.add("abc");
System.out.println("线程A添加元素,此时list的size为:" + list.size());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (list.size() == 5)
condition.signal();
}
lock.unlock();
});
//线程B
Thread threadB = new Thread(() -> {
lock.lock();
if (list.size() != 5) {
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程B收到通知,开始执行自己的业务...");
lock.unlock();
});
threadB.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
threadA.start();
}
}其中A 在唤醒操作之后,并不释放锁
LockSupport 阻塞和唤醒
可以指定唤醒某个线程
public static void main(String[] args) {
List<String> list = new ArrayList<>();
//线程B
final Thread threadB = new Thread(() -> {
if (list.size() != 5) {
LockSupport.park();
}
System.out.println("线程B收到通知,开始执行自己的业务...");
});
//线程A
Thread threadA = new Thread(() -> {
for (int i = 1; i <= 10; i++) {
list.add("abc");
System.out.println("线程A添加元素,此时list的size为:" + list.size());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (list.size() == 5)
LockSupport.unpark(threadB);
}
});
threadA.start();
threadB.start();
}参考:
https://blog.csdn.net/hbtj_1216/article/details/109655995
https://mp.weixin.qq.com/s/92o_4XezrbMv_-vyB8qeYQ

